I do enough MS SQL Server work every day that I thought it was worth spending a little bit of time writing about five optimisation techniques that I think about every time I need to work on a query. Very often I see code that doesn’t consider these issues and it can make a huge difference to the runtime of a stored procedure, the memory/CPU usage, and even the time it takes you to test things.
I’ll be using the StackOverflow2010 database to demonstrate some points, available here, thanks to Brent Ozar’s work to transform the XML into a SQL database. Full attribution to the Stack Exchange Network for the data.
This is all done on Microsoft SQL Server 2017, so yes I’m a little behind but these principles still apply.
1. Filter earlier
Rather then using SELECT * INTO #TEMP FROM dbo.TABLE and then using #TEMP, in a misguided attempt to reduce blocking on dbo.TABLE, have a think about what records you are interested in and try to filter to them as early as possible. For example, if you only need records with a timstamp in the year 2009, and PostTypeId = 2, use that as early as you can. There is no point having the engine scan large tables again and again if there is data you know you don’t need, even if it’s a temporary table. You can still cause other sessions to wait if you’re hogging all of the space in tempdb.
Old:
USE StackOverflow2010
GO
DROP TABLE IF EXISTS #ALL_POSTS
SELECT *
INTO #ALL_POSTS
FROM dbo.Posts
SELECT AnswerCount,
CommentCount
FROM #ALL_POSTS
WHERE PostTypeId = 2
AND CreationDate BETWEEN '2009-01-01' AND '2009-12-31'
New:
USE StackOverflow2010
GO
DROP TABLE IF EXISTS #ALL_POSTS_FILTERED
SELECT AnswerCount,
CommentCount
INTO #ALL_POSTS_FILTERED
FROM dbo.Posts
WHERE PostTypeId = 2
AND CreationDate BETWEEN '2009-01-01' AND '2009-12-31'
2. Use existing indexes
Querying against an existing index is almost always going to be a better idea that not using it, if you can. If the existing index is on CreationDate and then PostTypeId, don’t start your query with SELECT * FROM dbo.Posts WHERE PostTypeId = 2 if you are only interested in data from the past year, then query on CreationDate as well, and you can turn a scan of the whole index into a nice narrow seek.
Since StackOverflow2010 doesn’t have a lot of nice indexes yet (all tables just have clustered indexes on the ID column), I’ll create one first:
USE StackOverflow2010
GO
CREATE NONCLUSTERED INDEX IDX_Posts_CD_PTI ON dbo.Posts ( CreationDate, PostTypeID ) INCLUDE ( AnswerCount, CommentCount )
Now, we can see the two different execution plans for the two versions.
Old:
USE StackOverflow2010
GO
DROP TABLE IF EXISTS #POSTS_TYPE_2
SELECT *
INTO #POSTS_TYPE_2
FROM dbo.Posts
WHERE PostTypeId = 2
SELECT AnswerCount,
CommentCount
FROM #POSTS_TYPE_2
WHERE CreationDate BETWEEN '2009-01-01' AND '2009-12-31'
Here is the execution plan, using a large scan then scan again:
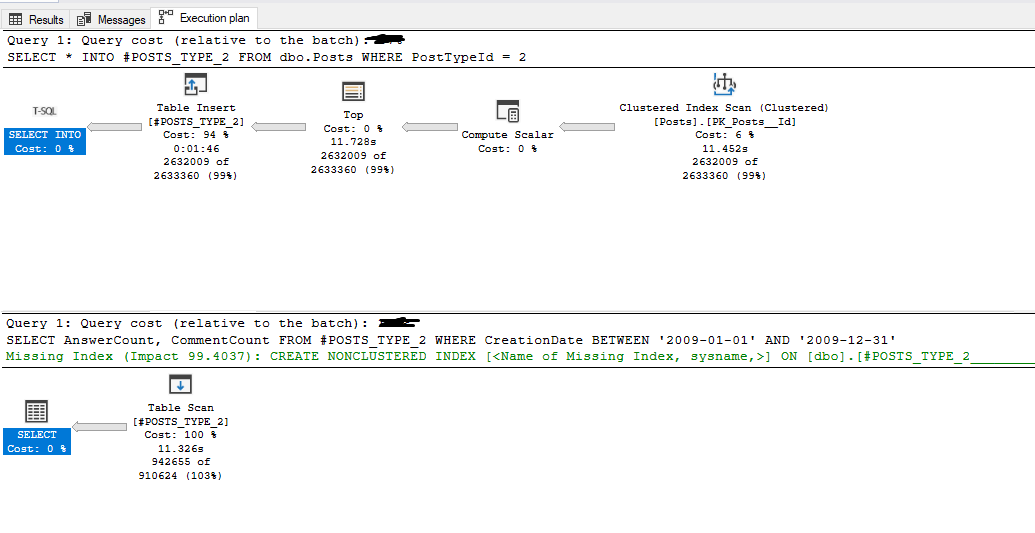
New:
SELECT AnswerCount,
CommentCount
FROM dbo.Posts
WHERE PostTypeId = 2
AND CreationDate BETWEEN '2009-01-01' AND '2009-12-31'
Execution plan, using just a seek (and it runs a lot faster, seconds compared to minutes):

3. SELECT only what columns you need
SELECT * is not good. Get out of the habit of writing that in your queries. Whenever you can, specify exactly what columns you need. Not only does it make it easier for the engine to not have to store extra data in memory or tempdb, or retrieve data it doesn’t need, it also future-proofs your code a little more. It is quite annoying to have a stored procedure start throwing an error, and it turns out someone used
SELECT *
INTO #POSTS_AND_TYPE
FROM dbo.Posts AS P
INNER JOIN dbo.PostTypes AS PT
ON PT.Id = P.PostTypeId
and a new column was added to dbo.PostTypes (say, “Tags” for some reason) that matches the name of a column in dbo.Posts, and then you get the fun error “Column names in each table must be unique. Column name ‘Tags’ in table ‘#POSTS_AND_TYPE’ is specified more than once.”.
Just don’t do it. Be specific.
4. Use temp tables to reduce lookups on big tables
Whilst I advise against blindly using temp tables, especially with SELECT * INTO #TEMP (seriously, I’ve seen far too many instances of people making full copies of tables into one called #TEMP, which ends up hurting performance as the temporary table doesn’t have the existing indexes), it can be helpful to use them sometimes to reduce lookups to very large tables, especially if you are using parameters that make it hard for the engine to estimate how many rows will be returned.
As an example (slightly contrived, I know), consider the following query (I’m just joining some random tables and getting some random columns):
USE StackOverflow2010
GO
SELECT P.AnswerCount,
P.ClosedDate,
V.BountyAmount,
U.Age,
U.DownVotes,
U.DisplayName,
B.[Name]
FROM DBO.Posts AS P
INNER JOIN DBO.Votes AS V
ON V.PostId = P.Id
INNER JOIN DBO.Users AS U
ON U.Id = P.OwnerUserId
INNER JOIN DBO.Badges AS B
ON B.UserId = U.Id
WHERE U.UpVotes + U.DownVotes > 10000000
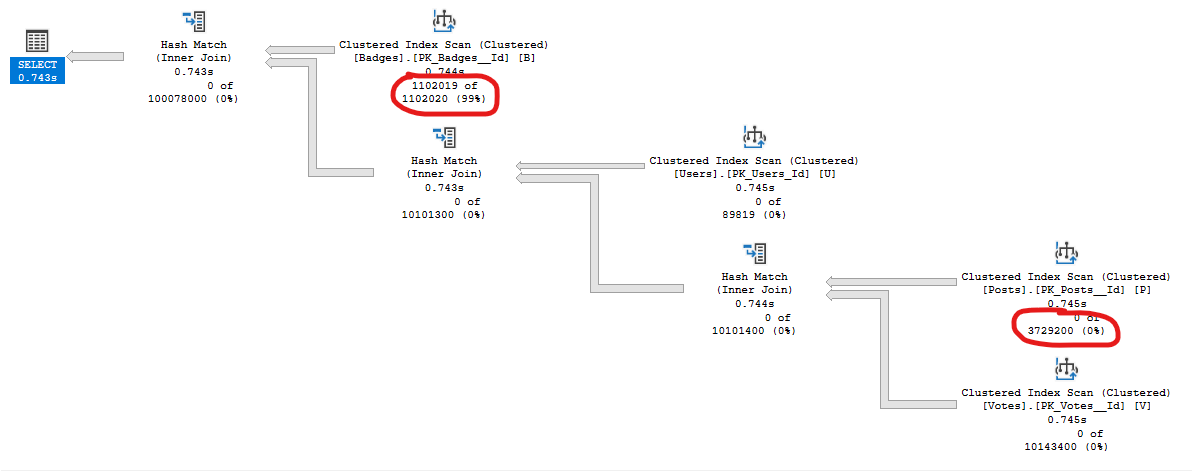
This will return no rows since no user has over 10,000,000 votes. However, from the parts of the execution plan highlighted below, you can see that (a) the engine estimated that 3,729,200 rows would be returned from Users, and (b) that it ended up scanning 1,102,019 rows from the Badges table, thinking there would be many matches. This is wasted CPU. If you want to know where the estimate of 3,729,200 comes from, read Brent Ozar’s post here
If we instead check the Users table first for any rows with over 10,000,000 votes, and then use that temp table like this…
DROP TABLE IF EXISTS #POSTS
SELECT Age,
DownVotes,
Id,
DisplayName
INTO #USERS
FROM DBO.Users
WHERE UpVotes + DownVotes > 10000000
SELECT P.AnswerCount,
P.ClosedDate,
V.BountyAmount,
U.Age,
U.DownVotes,
U.DisplayName,
B.[Name]
FROM dbo.Posts AS P
INNER JOIN DBO.Votes AS V
ON V.PostId = P.Id
INNER JOIN #USERS AS U
ON U.Id = P.OwnerUserId
INNER JOIN DBO.Badges AS B
ON B.UserId = U.Id
…then the engine knows that INNER JOINS to an empty table will produce no results, so all of the scans show 0 in the second query:
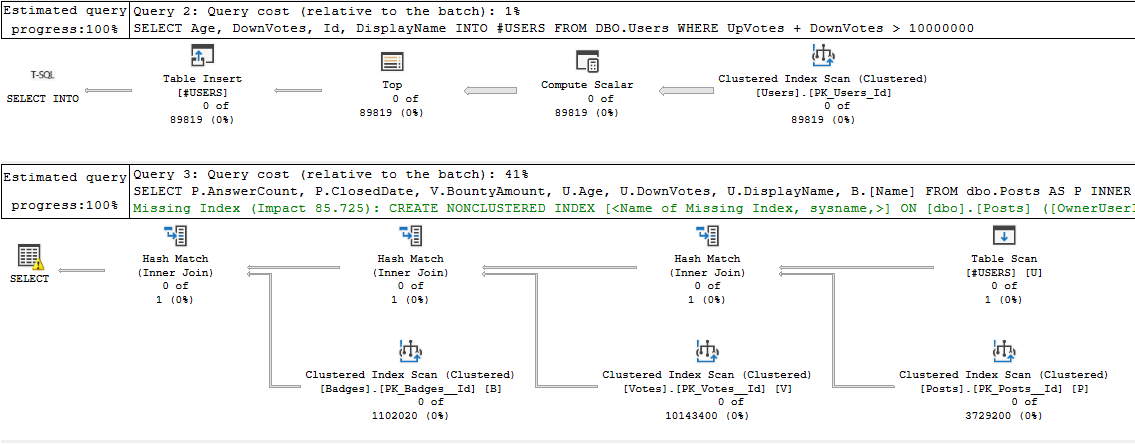
Of course the difference won’t always be 3,729,200 rows vs 0 rows, but it can still help a lot, especially if the query involves a lot of joins, or you don’t have indexes you can use.
5. Avoid functions and operators on joins
Basically, functions can be painful. The newer versions of SQL are getting better at in-lining functions, but it doesn’t always work. They can prevent queries from going parallel (which is where the engine uses multiple CPU cores), mess with row estimates, and get run many times instead of just once. Plus, you usually can’t use an existing index on that column. If you’re going to be doing joins with large tables, I would always suggest creating a new column with the function pre-calculated before using it in the join.
To go into a bit more detail, let’s look at using a function in a WHERE. First, I’ll create a simple function to take a user’s location and return the text before the first comma:
CREATE FUNCTION DBO.LocationBeforeComma( @Location NVARCHAR(100) )
RETURNS NVARCHAR(100)
AS
/*Find the text in the Location field up to the first comma.
If there is no comma, return the whole input unchanged*/
BEGIN
DECLARE @BeforeFirstComma NVARCHAR(100) =
IIF(
@Location LIKE '%,%',
LEFT( @Location, CHARINDEX( ',', @Location ) - 1 ),
@Location
)
RETURN @BeforeFirstComma
END
GO
Then, I will create an index on Location (just to show it doesn’t help reduce the estimated rows):
CREATE NONCLUSTERED INDEX IDX_Users_L ON dbo.Users ( Location )
Then I can use that function to find users whose location starts with “Sydney”:
SELECT U.Location,
dbo.LocationBeforeComma( U.Location )
FROM dbo.Users AS U
WHERE dbo.LocationBeforeComma( U.Location ) = 'Sydney'
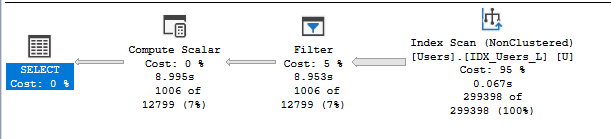
The execution plan doesn’t look too bad. Yes it has the scan the whole index as its on “Location”, not “LocationBeforeComma( Location )” but it doesn’t take too long on this 2010 version of the database.
However, if I dig into it a little more, I can see that the function is not actually called just once, like you might expect for set-based logic, but once for each row. To show that, I will create an extended events session to track function runs (inspired, once again, from Brent Ozar here)
First, create the session:
CREATE EVENT SESSION [CaptureFunctionExecutions] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
ACTION(sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.sql_statement_completed(
ACTION(sqlserver.sql_text,sqlserver.tsql_stack))
ADD TARGET package0.ring_buffer
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
Then in the SSMS Object Explorer, at the server level, go to Management -> Extended Events -> Sessions -> CaptureFunctionExecutions, right click and start, then right click and Watch Live Data.
Now if I run the above code to find all users whose location starts with “Sydney”, you can see in the extended events window that the function is executed many, many times.
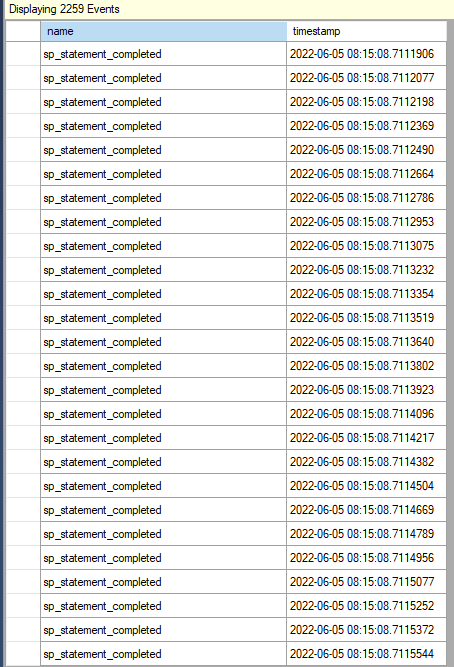
This function is relatively simply, but you can image what this means if the function has queries to other tables, a few joins - very quickly the performance becomes awful. Be careful with using function in there WHERE clause and ON for joins.
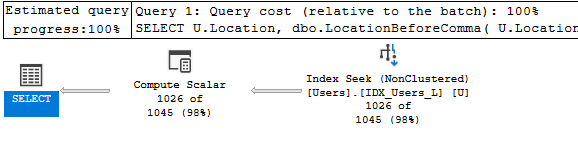
In this specific case, you’d be better served using the LIKE operator, which would allow the engine to use the index, showing a nice index seek with an estimate very close to the final number of returned rows:
SELECT U.Location,
dbo.LocationBeforeComma( U.Location )
FROM dbo.Users AS U
WHERE U.Location LIKE 'Sydney%'
Bonus: Learn to read execution plans
I’ve used a few screenshots from execution plans to demonstrate my points, without explaining in too much detail how to read them. However, being able to interpret execution plans is a great help in optimising queries and finding bottlenecks. Since this is a bonus point, I’ll simply point you to some other resources and encourage you to do some googling: